SemanticKITTI
A Dataset for Semantic Scene Understanding using LiDAR Sequences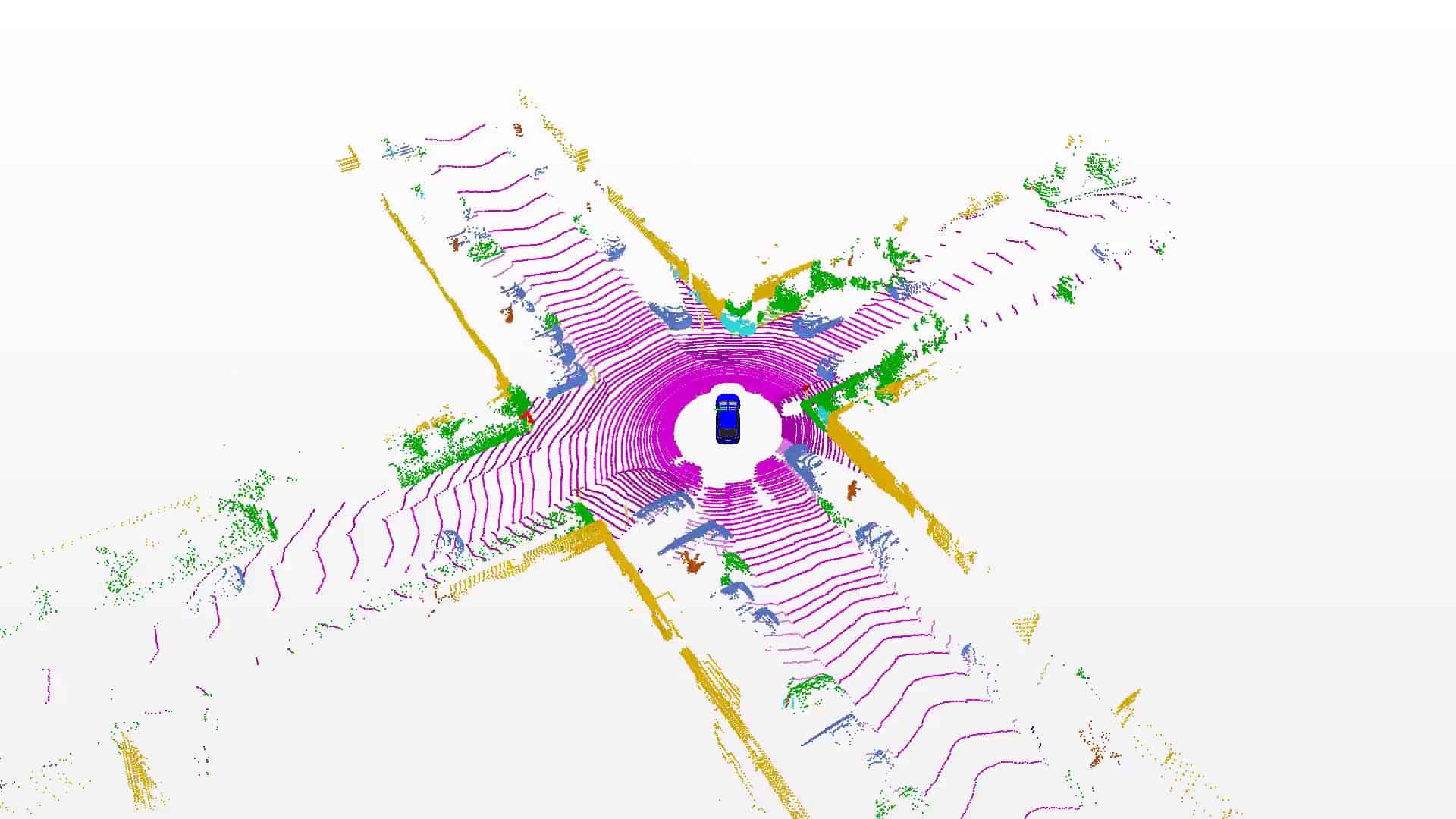
SemanticKITTI
A Dataset for Semantic Scene Understanding using LiDAR Sequences
Large-scale
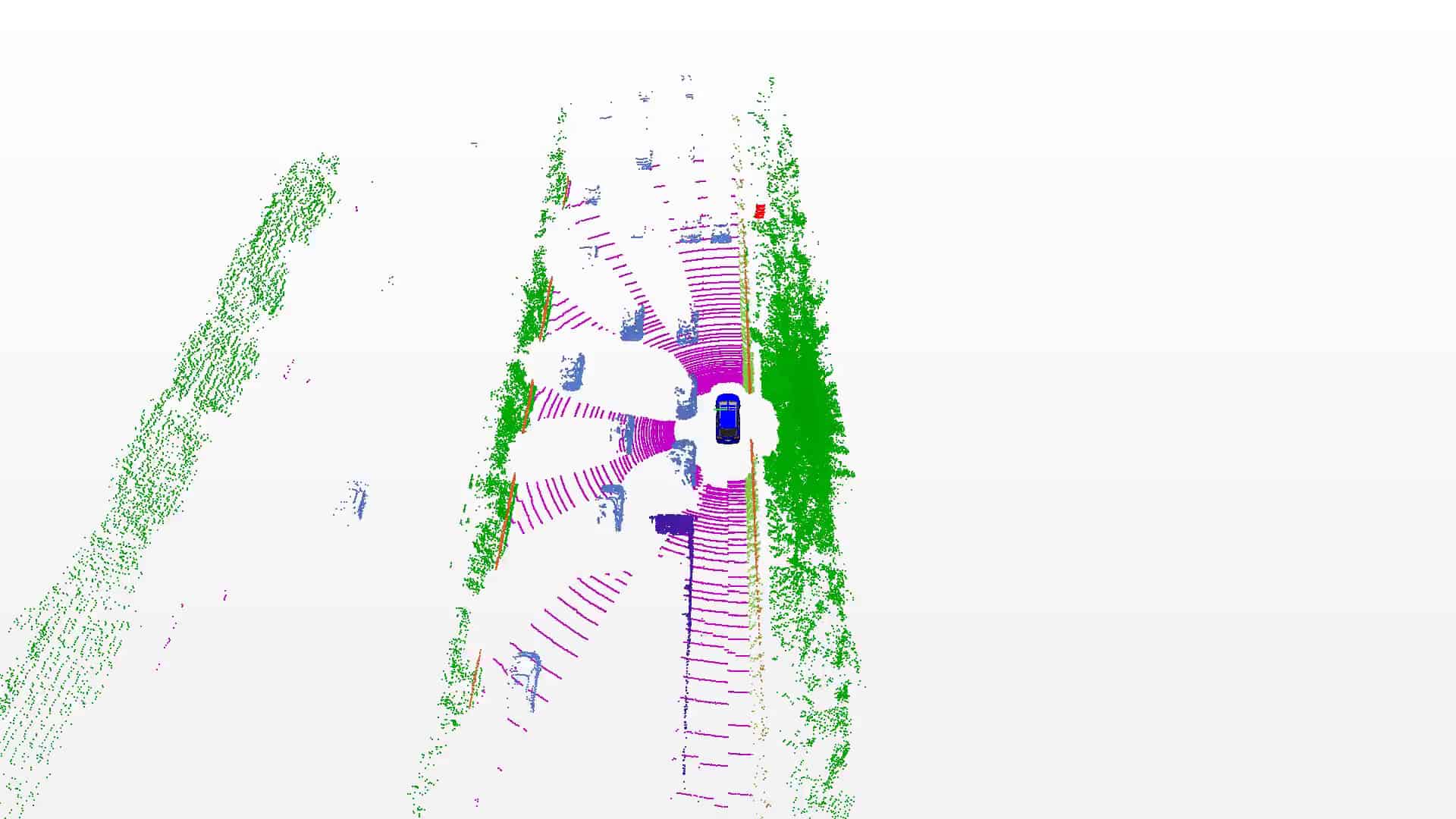
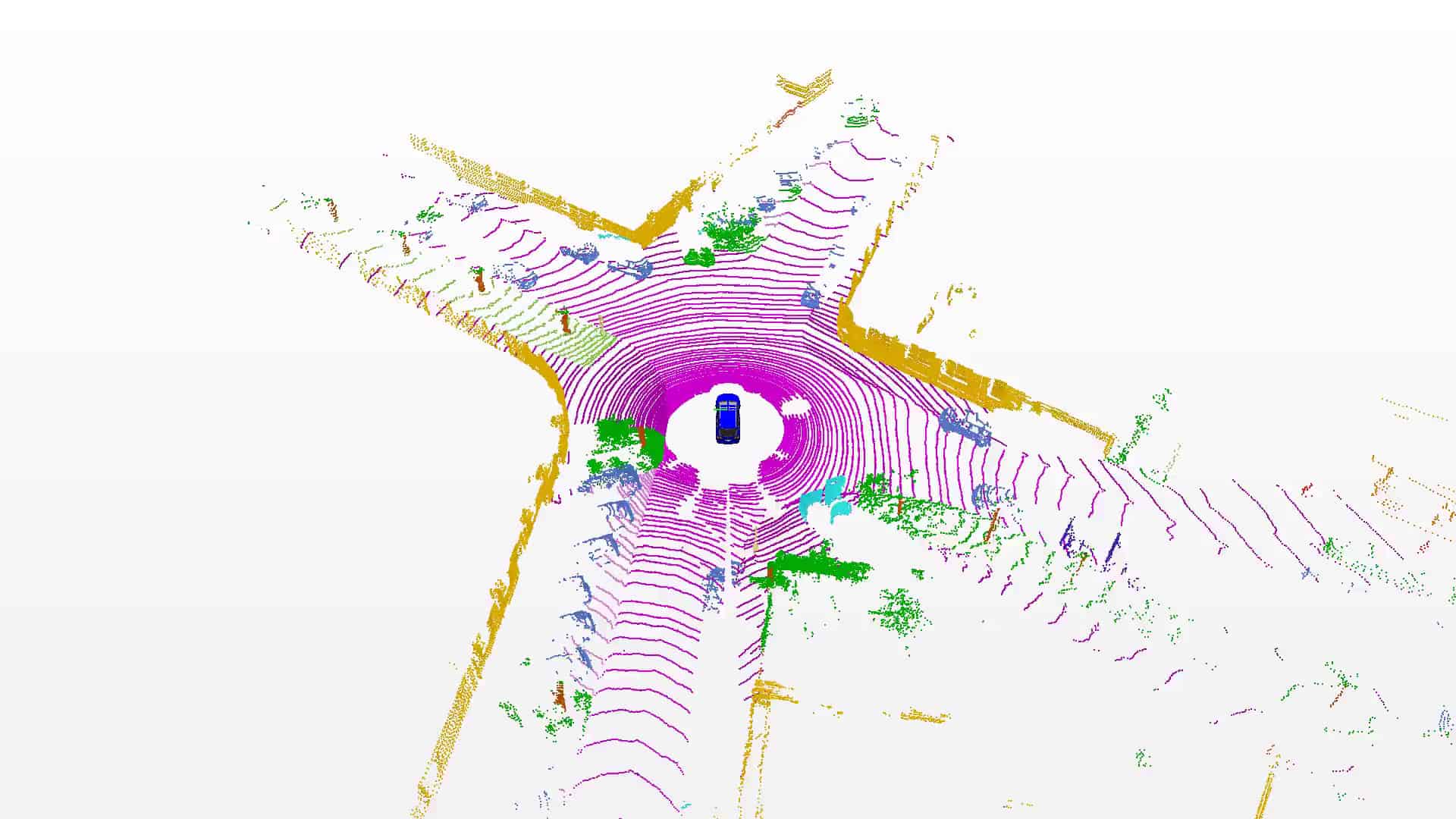
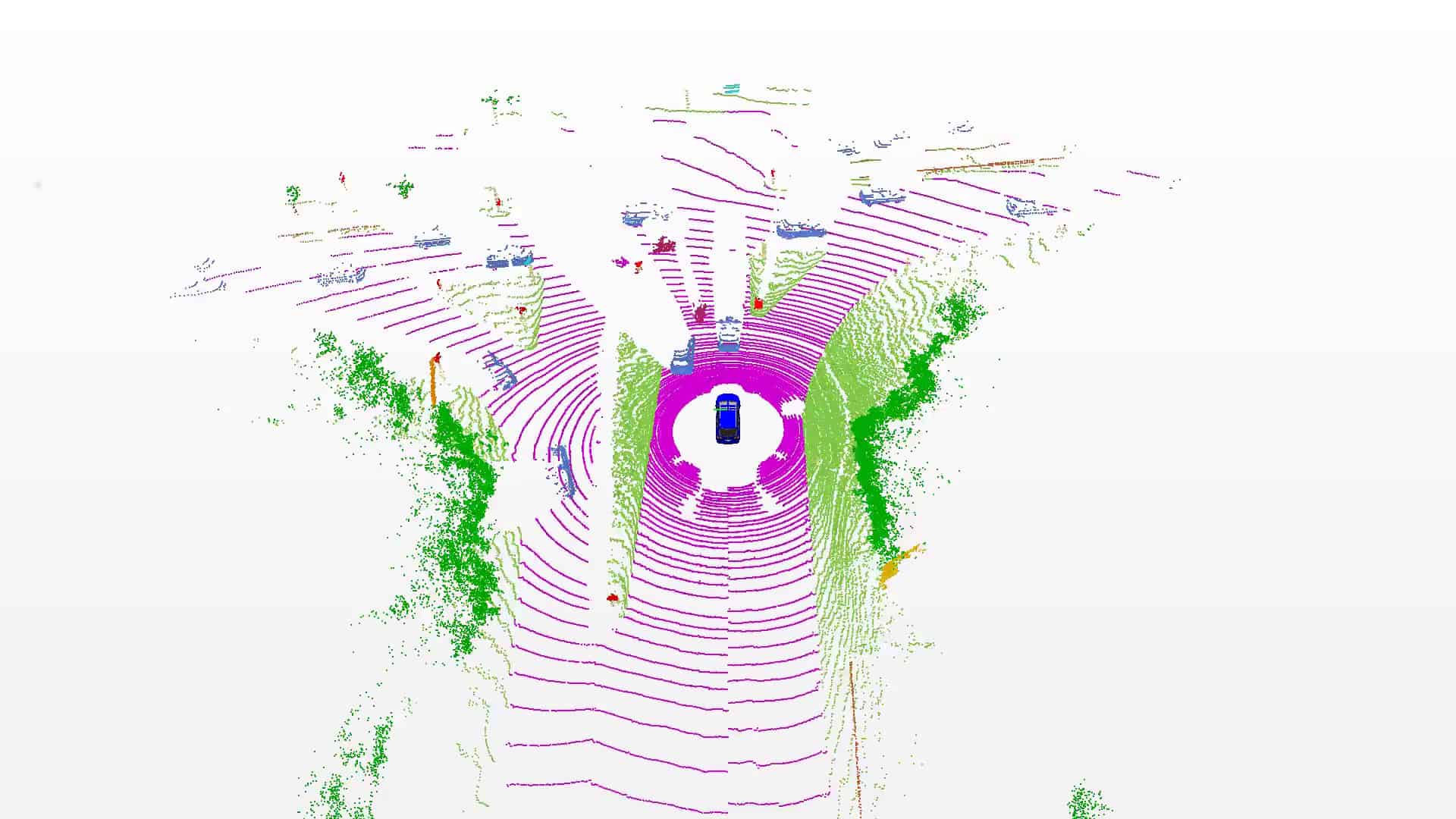
SemanticKITTI is based on the KITTI Vision Benchmark and we provide semantic annotation for all sequences of the Odometry Benchmark. Overall, we provide an unprecedented number of scans covering the full 360 degree field-of-view of the employed automotive LiDAR.

Sequential
We labeled each scan resulting in a sequence of labeled point clouds, which were recorded at a rate of 10 Hz. This enables the usage of temporal information for semantic scene understanding and aggregation of information over multiple scans.

Dynamic
We annotated moving and non-moving traffic participants with distinct classes, including cars, trucks, motorcycles, pedestrians, and bicyclists. This enables to reason about dynamic objects in the scene.
News
| Aug 31, 2022 | Competitions transferred to new Codalab servers! See tasks for new links! |
| Feb 01, 2021 | Added moving object segmentation (link). |
| Sep 15, 2020 | Added 4D panoptic segmentation (link). |
| Aug 24, 2020 | Updated semantic scene completion. |
| Apr 1, 2020 | Added panoptic segmentation task, code and competition (link). |
| Added leaderboards for published approaches. | |
| Dez 06, 2019 | Added semantic scene completion task, code and competition (link). |
| Aug 19, 2019 | Competition for semantic segmentation (link) online and release of the point cloud labeling tool (link). |
| Jul 15, 2019 | Release of dataset including instance annotation for all traffic participants (static and moving). |
Paper
See also our paper for more information and baseline results:


If you use our dataset or the tools, it would be nice if you cite our paper (PDF) or the task-specific papers (see tasks):
@inproceedings{behley2019iccv,
author = {J. Behley and M. Garbade and A. Milioto and J. Quenzel and S. Behnke and C. Stachniss and J. Gall},
title = {{SemanticKITTI: A Dataset for Semantic Scene Understanding of LiDAR Sequences}},
booktitle = {Proc. of the IEEE/CVF International Conf.~on Computer Vision (ICCV)},
year = {2019}
}More information on the dataset can be found in our recent IJRR dataset paper (PDF):
@article{behley2021ijrr,
author = {J. Behley and M. Garbade and A. Milioto and J. Quenzel and S. Behnke and J. Gall and C. Stachniss},
title = {{Towards 3D LiDAR-based semantic scene understanding of 3D point cloud sequences: The SemanticKITTI Dataset}},
journal = {The International Journal on Robotics Research},
volume = {40},
number = {8-9},
pages = {959-967},
year = {2021},
doi = {10.1177/02783649211006735}
}But also cite the original KITTI Vision Benchmark on which the dataset is based on:
@inproceedings{geiger2012cvpr,
author = {A. Geiger and P. Lenz and R. Urtasun},
title = {{Are we ready for Autonomous Driving? The KITTI Vision Benchmark Suite}},
booktitle = {Proc.~of the IEEE Conf.~on Computer Vision and Pattern Recognition (CVPR)},
pages = {3354--3361},
year = {2012}
}